Twitter data mining with Python and Gephi: Case synthetic biology

Twitter is a source of latest commentary and signals on various topics. Whether it is a good or representative source depends on the topic. I recently decided to look into using tweets as a way to understand what the conversation in social media about synthetic biology is and who participates in it. I chose synthetic biology as a topic, since I have been working on a project exploring the future developments of synthetic biology and thus was a bit familiar with the subject. I also had a hidden agenda: to learn Python and Gephi. Here’s a brief description of what I learned from my play session with Twitter, Python and Gephi.
Gathering data
The obvious first step was to gather the tweets I wanted to single file, so I could structure and analyse them further. I decided to gather tweets with the word “synbio” (short for synthetic biology) in it, since it is fairly widely used among those who tweet about synthetic biology. Twitter offers a REST API for reading and writing tweets, but I ran into some problems with it. Problem 1: there is a restriction on how many requests can be sent in a given time, in order to prevent the system from overloading. Problem 2, which was the major one: you can only gather tweets from about last 7 days.
It is, however, possible to see older tweets through the Twitter website, all you need to do is keep scrolling down. The added bonus is that there is no need for setting up an API key or worrying too much about time limits. The downside is that there is not as much data available through the webpage, but the basics are there: date, user, tweet, and number of retweets and favorites. After a bit of Googling I discovered that it is indeed possible to control a browser with python, for example with Selenium. I wrote a script to load the Twitter search page for a given keyword and scroll down a number of times:
driver.get(
https://twitter.com/search?f=tweets&vertical=default&q=synbio&src=typd
") #get the page for i in range(1,100): self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") #scroll down time.sleep(3) #wait a bit for the page to load
After the script had run, I copied the text to a text file and continued if necessary. It is possible to limit the search to a certain time range using “until=2014-01-01” in the url. These and other options for refining the search can be found in the Twitter advanced search page.
Structuring data
After letting the algorithm enjoy its browsing, I had a long text file full of tweets. I only gathered tweets from 2015, although I could have gone all the way back to the beginning of twitter to 2006. Anyhow I had enough tweets (9609) to make some meaningful data mining. The next task was to structure this mess into something that can be mined. Regular expressions are a good tool to help in this. They may seem intimidating at first (and second and third) glance, but they are really powerful for searching text. After going through the basic course offered online by Code Academy, I understood them enough for my purposes.
I looked at the text file and noticed that each tweet ended with “favorites”, denoting the number of favourites the tweet had. I also noticed that before the tweet there were two line breaks, the day had a dot at the end, year was followed by a line break etc. What made things even simpler was that the twitter webpage had identified me as a Finn browsing from Finland, and everything else except the tweets were in finnish, making it rather easy to identify words or expressions that were very unlikely to appear in the tweets itself. I managed to structure the text into a neat little CSV file using magical python spells such as:
tweetList = re.split(r'suosikki\n|suosikkia\n', rawData) #split the text into tweets using the regular expression of “favourite(s)” which is “suosikki” or “suosikkia” in finnish match = re.search(r"@[^ ]+", str(tweet)) #search for something beginning with @ and ending with whitespace, so basically a username text = re.sub(r'\n', ' ', text) #remove linebreak from text
Now I had a file to look at in Excel and I drew a nice little graph, because that is what you do in Excel. But the lure of Python called me back and I continued analyzing the text, extracting mentions from tweets and making a network of who has mentioned who. Networks can be plotted directly from Python or wrote as a Gephi file, but I used a more cumbersome method of writing the network to CSV files and importing it to Gephi. I like to see the data in a spread sheet and am a prisoner of old habits.
Tweets in Excel
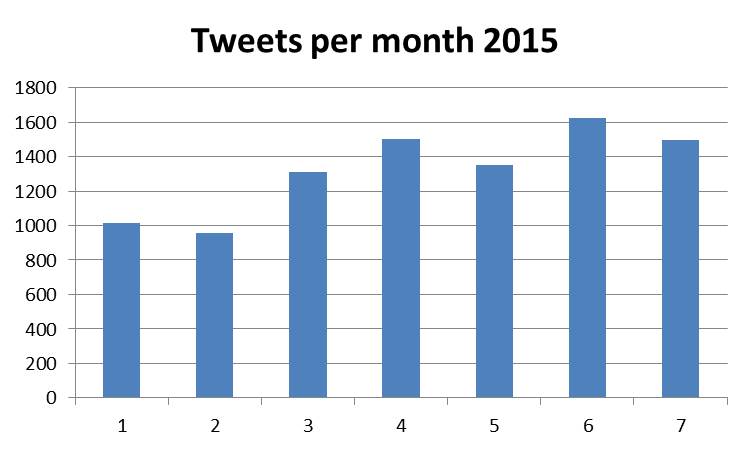
Tweets mentioning synbio per month
Gephi is a fantastic open source program for drawing and analysing networks. It has built in tools for all sort of things, such as clustering and data analysis. I used the Force Atlas layout to structure the network of mentions and resized the nodes (i.e. users) based on the number of other nodes pointing to them. The result is a network graph showing who gets the most mentions and by whom in tweets containing “synbio”.

Snapshot of mention network, click for full pdf
Analyse the data
Next I decided to analyse the tweets themselves, looking at common words and phrases to get an idea of what the tweets were about. Basically I wanted to know what words and concepts are connected to synthetic biology in the twittersphere. Luckily, there’s a handy toolkit for doing this, called nltk or natural language toolkit. It makes it easy to analyse word frequencies, remove common words and calculate word collocations, that is words that appear together. My process for creating a word collocation network was:
Find the most common not common words. I first looked at all the tweets, removed common words found in the Brown corpus, and made a list of 100 most common remaining words. This was to prevent the network from having too many nodes while keeping the most mentioned relevant ones. Synthetic biology is a forgiving topic in this sort of filtering, because most of the relevant words are rare in common parlance (like genetic, diybio, biotech). Here are some of the pythonese I used:
#divide to words tokenizer = RegexpTokenizer(r'\w+') words = tokenizer.tokenize(tweets) #remove more common words based on the brown corpus fdist = FreqDist(brown.words()) mostcommon = fdist.most_common(100) mclist = [] for i in range(len(mostcommon)): mclist.append(mostcommon[i][0]) words = [w for w in words if w not in mclist] #keep only most common words fdist = FreqDist(words) mostcommon = fdist.most_common(100) mclist = [] for i in range(len(mostcommon)): mclist.append(mostcommon[i][0]) words = [w for w in words if w in mclist]
Go through the tweets and calculate word collocations. First I removed common words from the tweets. Then, if two words were close to each other, they formed a pair, which I collected to a undirected graph. I also counted how many times each word was mentioned. Some useful pythonese included:
#find word pairs finder = BigramCollocationFinder.from_words(words, window_size = 5) pairs = sorted(finder.ngram_fd.items(), key=lambda t: (-t[1], t[0]))
Write it all to CSV an import to Gephi. Not surprisingly, synbio, synthetic and biology appeared often together. To bring the focus more to other words, I deleted them in Gephi and fine-tuned the remaining graph.

Word collocation graph, click for pdf
Create a dynamic graph
The final thing I tried was to make a dynamic graph, that is one that changes over time. This way I could look at which words appeared when. But mainly I just wanted to make an even more confusing and cool looking graph. I already had the word collocations and dates of tweets, so the biggest challenge was to understand the format in which Gephi wants the dynamic data to be. The time intervals need to be input as <(start_1,end_1),(start_2, end_2),…,(start_n,end_n)> and the start and end can be either a float or a date (yyyy-mm-dd). Dates make the graph more readable, so I opted for them. I set the “duration” of each tweet to one day, played with Gephi a bit and voilà:
[embed]https://www.youtube.com/watch?v=j_uTJDMipNI[/embed]
Use in foresight?
Understanding the current discussion, how it has evolved and who are the people involved in it is crucial for identifying the key drivers and tensions that shape the future. Twitter offers one rather structured source of discussion data. However, after this exercise I'm still a bit puzzled about what to think about the results. Thus perhaps the biggest lesson I learned from this exercise was that while it is relatively easy to make graphs and calculate statistics, drawing clever insights from the data is the hard part.